TealFlow: Automating Clinical Reporting Apps with AI and {teal}

You’ve requested development support for a survival analysis application aligned with your SAP, but the team’s capacity means it’ll be at least three weeks before they can start.
Clinical statisticians and pharma data scientists, does this sound like your average Wednesday?
Your clinical study data is ready for analysis, sponsor deadlines are approaching, and you know exactly what kind of app you need - but you can't build it yourself. You speak in terms of Cox proportional hazards models, while the development team thinks in React components. Every email adds another day to your timeline, and generic AI tools like GitHub Copilot don't understand pharmaceutical validation requirements.
It’s a struggle, but there’s a silver lining.
TealFlow solves your problems by letting you describe analysis needs in plain statistical language. It then generates {teal} applications that follow FDA submission standards. You can go from providing your study datasets to having a working survival analysis dashboard in under an hour, with code that your validation team can review and approve.
In this article, we’ll walk you through TealFlow's technical architecture, show a complete time-to-event analysis workflow, and explain how it integrates with your existing GxP validation processes.
The Bottleneck In Pharma Tech Teams
Your biostatistician needs a forest plot visualization for next week's regulatory meeting, but your development team doesn’t have the time to even look at the request until next month.
This scenario plays out daily across pharmaceutical companies. Technical teams face request backlogs that stretch resources beyond their limits. A “simple” request becomes a two-week project when it should take two hours.
The root problem is the communication gap between statisticians and developers.
When a statistician asks for "Kaplan-Meier curves, Cox proportional hazards models, and associated visualizations," the developer hears technical requirements that need translation, clarification, and multiple rounds of back-and-forth emails.
Then there's compliance.
Regulatory validation requirements add weeks to every project. Every line of code needs documentation. Every calculation requires traceability. Everything must meet FDA submission standards. A quick prototype becomes a formal software development lifecycle with change control procedures and validation protocols.
Generic AI coding assistants can't help here either.
Tools like GitHub Copilot understand JavaScript and Python, but they don't know pharmaceutical frameworks:
- They can't generate apps that follow your company's validation standards
- They don't understand CDISC data structures or regulatory submission requirements
You end up with generic Shiny code that needs major rework before it can be declared usable.
The result? Critical analyses sit in backlogs while regulatory deadlines approach.
Let us show you a better way.
Rise of R and Shiny In Regulatory Submissions
R is replacing SAS as the language of pharmaceutical analysis. What’s even better is that regulators are welcoming the change.
In the pharmaceutical industry, this represents a shift from proprietary statistical software that dominated for decades. Companies like Novo Nordisk, Roche, and Johnson & Johnson have already made R a central part of their regulatory submission strategies.
The numbers tell a clear story.
According to the 2024 Japan Pharmaceutical Manufacturers Association survey, 59% of pharmaceutical companies have adopted R, with 37.5% of them having submitted TLFs using R and R programs for TLFs. Among the 23 top pharma companies surveyed by Pharmaverse, 20 reported increasing R usage for clinical reporting. 16 companies are either currently using or planning to use R for regulatory submissions to the FDA and PMDA.
But the really good news is regulatory acceptance.
The R Submissions Working Group proved that R-based submissions work in practice. Their pilot projects demonstrated that FDA reviewers can successfully evaluate R-generated analyses and outputs.
Three companies are already doing end-to-end R submissions to the FDA - Novo Nordisk, Roche, and Johnson & Johnson. Seven companies use R for specific submission components.
R's advantages over traditional tools are clear as day:
- Open ecosystem that keeps pace with evolving statistical methods
- Pharmaverse packages designed specifically for pharmaceutical workflows
- Publication-ready visualizations through ggplot2 and related libraries
- Cost-effective approach that eliminates expensive licensing fees
- Access to modern talent who prefer working with contemporary tools
Then there's Shiny.
R Shiny takes static analyses and transforms them into interactive applications that multiple stakeholders can use simultaneously. Shiny apps can both read from and write to databases, unlike traditional business intelligence tools that only display data. This means researchers can modify parameters, update analyses, and save findings within a single application.
Shiny's reactive programming model makes it easy for non-programmers to follow calculations and validate analytical approaches. When regulatory reviewers examine submission materials, they can trace through the logic without getting lost in complex code structures.
The R Submissions Working Group Pilot 4 demonstrated successful FDA submission of R Shiny applications. According to the 2024 JPMA survey, more than 60% of pharmaceutical companies expressed interest in submitting R Shiny applications following this proven pathway.
To conclude, your regulatory team now has a validated route from R analysis to FDA submission that doesn't require proprietary software.
Let’s see where `{teal}` comes in.
{teal} as the Modular Clinical Framework
{teal} is an open-source, scalable R/Shiny framework developed by Roche and Genentech. It was primarily developed to support clinical trial analysis, but over time, it became robust enough to handle a wide variety of general data exploration tasks.
If you’re new to {teal}, here are some key features you need to know:
- Dynamic filtering for tailored data exploration
- Code reproducibility via built-in code generation
- Report generation with easy export options
- Modular framework to enhance reusability
But for our technical audience, you probably just want to know how much effort it takes to get started with {teal}.
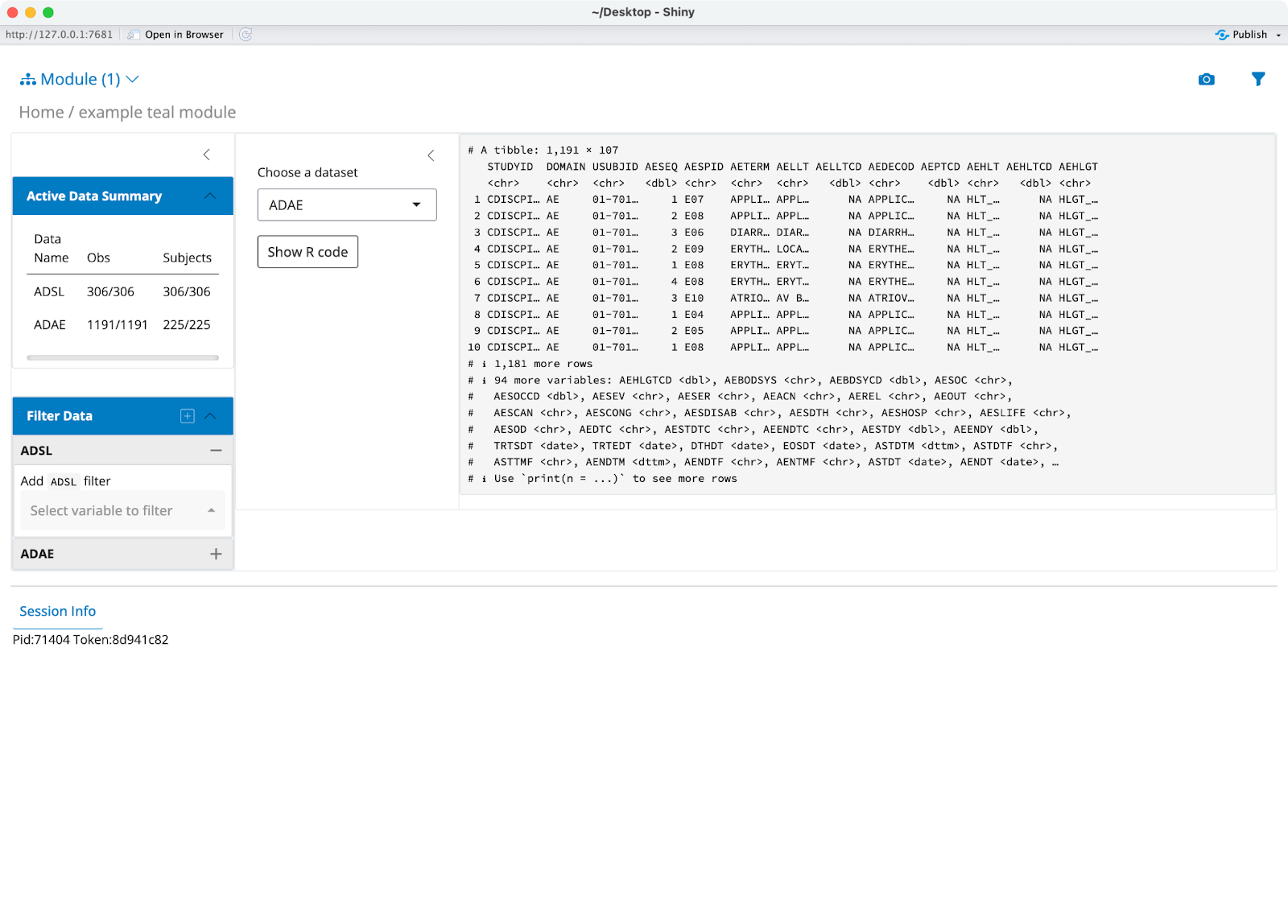
We’re pleased to report - not much. Here’s what you need to get a simple app running that uses datasets from the {pharmaverseadam} package.
First, install packages with {pak}:
Then, create `app.R` with the following contents and run the app:
That’s it! You now have a fully-working application that displays two datasets - ADAE and ADSL:
To get more hands-on with {teal}, we recommend the following resources:
- Shiny Gatherings x Pharmaverse: Building Clinical Data Analysis Apps with {teal}
- Simplifying Clinical Data Dashboards with {teal} and {pharmaverseadam}
- {teal} GitHub repo
How TealFlow Works Technically
In plain English, TealFlow turns your Statistical Analysis Plan into working {teal} applications through a three-stage AI pipeline: input analysis, module mapping, and code generation.
The process starts when you upload your clinical dataset. Then, through a chat interface, you can either upload your full Statistical Analysis Plan (SAP) to guide the analysis or keep it simple by describing a specific analysis goal. For example, you might say: "I want to analyze time-to-event data with Kaplan-Meier curves grouped by treatment arm."
This is what makes TealFlow different from generic AI assistants.
It specializes in pharmaceutical R frameworks. It knows the {teal} ecosystem inside out. When you mention survival analysis, TealFlow doesn't generate generic ggplot2 code - it suggests the appropriate teal modules that handle Kaplan-Meier curves, Cox proportional hazards models, and regulatory-compliant visualizations.
The AI engine maps your requirements to validated {teal} components.
Say you need to examine adverse events by system organ class. TealFlow recognizes this as a standard pharmaceutical use case and suggests specific modules from the {teal} library that handle:
- Safety data visualization
- Adverse event coding and filtering
- Regulatory-standard tabulations
- Interactive drill-down capabilities
But then it goes deeper than module selection.
TealFlow gives your mature Software Development Life Cycle (SDLC) a super-fast boost. It generates a high-quality codebase that serves as a robust starting point, following pharmaceutical industry standards. This accelerates development while maintaining full human control and adhering to your company's coding conventions. The output includes documentation and is structured to meet the validation requirements that regulatory submissions demand, ready for human review and integration into your existing process.
For statisticians working in pharmacy, conversational development changes how you work with applications.
Instead of submitting formal change requests, you refine applications through natural dialogue. "Can you add a filter for different dose groups?" or "I need to exclude patients who discontinued before day 30" is all it takes. TealFlow adapts the application in real-time, all while maintaining code quality and compliance standards.
This creates an AI feedback loop where each interaction improves both your immediate application and TealFlow's understanding of pharmaceutical workflows. The system learns from your preferences, coding standards, and analytical approaches.
You end up with a custom analytical tool in hours, not weeks.
Your technical team can focus on complex, high-value projects while researchers handle routine applications independently.
Statisticians can prototype multiple analytical approaches, meaning they test more hypotheses and validate more ideas at the same time.
It’s also worth noting that TealFlow outputs reviewer-ready R code that integrates directly into your existing validation workflows and can be used in FDA submissions following the proven R Submissions Working Group pathway.
Compliance Considerations: Reproducibility and Validation
AI-generated code doesn't guarantee compliance, but TealFlow was built with GxP validation in mind from day one.
When you submit to the FDA or EMA, auditors examine your code line by line. TealFlow addresses this through structured code generation that follows pharmaceutical validation standards: proper commenting, clear variable naming, modular functions, and documented data transformations.
Reproducibility comes from using version-controlled `{teal}` modules that have been tested and validated by the pharmaceutical community. You're getting proven components that follow established statistical practices and have been used in regulatory submissions.
The system maintains complete traceability from input to output:
- Which clinical datasets were used
- What statistical methods were applied
- Which `{teal}` modules were selected and why
- How parameters were configured
Code validation follows your existing processes. TealFlow generates transparent, documented R code that your technical team can review using the same validation procedures they use for manually-written applications.
Since TealFlow builds on the `{teal}` framework and follows R Submissions Working Group guidelines, your compliance team already knows how to validate and submit these applications.
To conclude, you get the speed benefit of AI without sacrificing the regulatory compliance that pharmaceutical submissions require - win-win.
Strategic Benefits for Technical Teams
TealFlow completely changes how pharmaceutical technical teams allocate their expertise.
When statisticians can build their own analytical tools, technical teams can focus on complex, high-value projects that truly require specialized development skills. Developers can work on custom integrations, advanced visualizations, and infrastructure challenges instead of spending weeks coding standard survival analysis dashboards.
In other words, biostatisticians handle routine `{teal}` applications independently while your development team works on problems that require deep technical expertise.
Faster iteration cycles change how clinical teams approach data analysis.
When researchers can prototype multiple analytical approaches simultaneously, they test more hypotheses within the same timeline constraints. Early-phase clinical development, where rapid hypothesis testing and data exploration are needed before committing to expensive late-stage trials, especially benefit from this speed.
The communication bottleneck disappears.
Technical teams no longer need to translate between statistical requirements and software specifications. When a statistician generates their own app and asks for specific technical enhancements, they're speaking from direct experience with the codebase rather than abstract requirements.
Team dynamics improve when everyone can focus on their areas of expertise.
Clinical researchers gain independence in building analytical tools. Technical teams can prioritize complex development work that requires their specialized knowledge. The result is higher productivity across both groups and faster time-to-insight.
Summing up Clinical Reporting with TealFlow
TealFlow addresses the specific challenges pharmaceutical technical teams face: request backlogs, communication gaps, and the need for regulatory-compliant code that generic AI assistants can't provide.
When clinical researchers can build their own analytical tools, technical teams are free to focus on their tasks. When statisticians iterate rapidly through analytical approaches, they test more hypotheses and can be more confident in their results.
Ready to test TealFlow with your actual clinical datasets?
Test it with your CDISC data. Compare generated `{teal}` applications against manually-built alternatives. Run the code through your validation procedures.
>For hands-on testing and technical discussions, contact the Appsilon team. Explore our vast collection of resources and case studies.
